Unified API
Note
Everything written here sounds real nice. However, we live in a practical world, and expect each platform to adhere to what makese sense for the developers there. What is written below is not to be taken as strict rules. It is a guide and to be thought of as a tool to help developers build SDKs which work well which eachother.
The top priority when building SDKs is a high quality API and developer experience, don’t let unified API be an excuse to build things which don't make sense for a given language.
Types Example: Typed languages might have very different developer experience than dynamic.
Platform Example: Does Rust have exceptions? Nope, don't name APIs for rust like captureException.
Unified API Example: We don't like Hubs and Scopes anymore, and we are redefining that, Hub & Scope Refactoring
New Sentry SDKs should follow the unified API, use consistent terms to refer to concepts. This documentation explains what the unified API is and why it exists.
Sentry has a wide range of SDKs that have been developed over the years by different developers and based on different ideas. This has lead to the situation that the feature sets across the SDKs are different, use different concepts and terms which has lead to the situation that it's often not clear how to achieve the same thing on different platforms.
Additionally those SDKs were purely centered around error reporting through explicit clients which meant that certain integrations (such as breadcrumbs) were often not possible.
We want a unified language/wording of all SDK APIs to aid support and documentation as well as making it easier for users to use Sentry in different environments.
Design the SDK in a way where we can trivially add new features later that go past pure event reporting (transactions, APM etc.).
Design the SDK that with the same client instance we can both work naturally in the runtime environment through dependency injection etc. as well as using an implied context dispatching to already existing clients and scopes to hook into most environments. This is important because it allows events to include data from other integrations in the process.
The common tasks need to be easy and obvious.
For helping 3rd party libraries the case of “non configured Sentry” needs to be fast (and lazily executed).
The common API needs make sense in most languages and must not depend on super special constructs. To make it feel more natural we should consider language specifics and explicitly support them as alternatives (disposables, stack guards etc.).
minimal: A separate "facade" package that re-exports a subset of the SDK's functionality through interfaces or proxies. That package does not directly depend on the SDK, instead it should make every operation a noop if the SDK is not installed.
The purpose of such a package is to allow random libraries to record breadcrumbs and set context data while not having a hard dependency on the SDK.
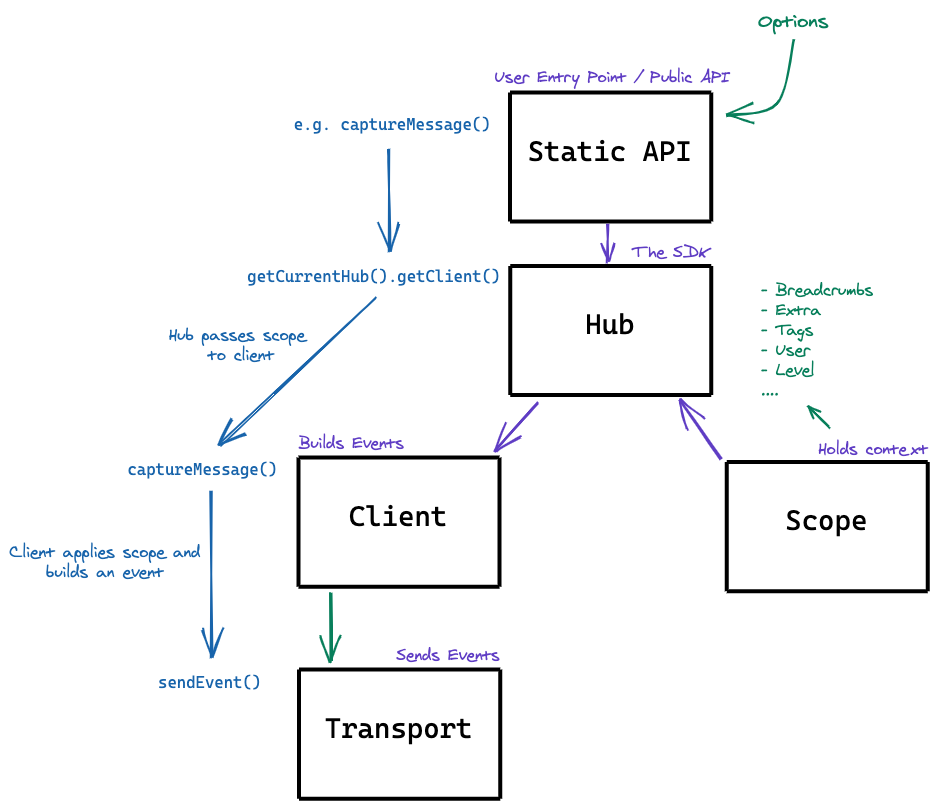
hub: An object that manages the state. An implied global thread local or similar hub exists that can be used by default. Hubs can be created manually.
scope: A scope holds data that should implicitly be sent with Sentry events. It can hold context data, extra parameters, level overrides, fingerprints etc.
client: A client is an object that is configured once and can be bound to the hub. The user can then auto discover the client and dispatch calls to it. Users typically do not need to work with the client directly. They either do it via the hub or static convenience functions. The client is mostly responsible for building Sentry events and dispatching those to the transport.
client options: Are parameters that are language and runtime specific and used to configure the client. This can be release and environment but also things like which integrations to configure, how in-app works etc.
context: Contexts give extra data to Sentry. There are the special contexts (user and similar) and the generic ones (
runtime,os,device), etc. Check out Contexts for some predefined keys - users can also add arbitrary context keys. Note: In older SDKs, you might encounter an unrelated concept of context, which is now deprecated by scopestags: Tags can be arbitrary string→string pairs by which events can be searched. Contexts are converted into tags.
extra: Truly arbitrary data attached by client users. Extra should be avoided where possible, and instead structured
contextshould be used - as these can be queried and visualized in a better way.transport: The transport is an internal construct of the client that abstracts away the event sending. Typically the transport runs in a separate thread and gets events to send via a queue. The transport is responsible for sending, retrying and handling rate limits. The transport might also persist unsent events across restarts if needed.
integration: Code that provides middlewares, bindings or hooks into certain frameworks or environments, along with code that inserts those bindings and activates them. Usage for integrations does not follow a common interface.
event processors: Callbacks that run for every event. They can either modify and return the event, or
null. Returningnullwill discard the event and not process further.See Event Pipeline for more information.
disabled SDK: Most of the SDK functionality depends on a configured and active client. Sentry considers the client active when it has a transport. Otherwise, the client is inactive, and the SDK is considered "disabled". In this case, certain callbacks, such as
configure_scopeor event processors, may not be invoked. As a result, breadcrumbs are not recorded.
The static API functions is the most common user facing API. A user just imports these functions and can start emitting events to Sentry or configuring scopes. These shortcut functions should be exported in the top-level namespace of your package. Behind the scenes they use hubs and scopes (see Concurrency for more information) if available on that platform. Note that all listed functions below are mostly aliases for Hub::get_current().function.
init(options): This is the entry point for every SDK.
This typically creates / reinitializes the global hub which is propagated to all new threads/execution contexts, or a hub is created per thread/execution context.
Takes options (dsn etc.), configures a client and binds it to the current hub or initializes it. Should return a stand-in that can be used to drain events (a disposable).
This might return a handle or guard for disposing. How this is implemented is entirely up to the SDK. This might even be a client if that’s something that makes sense for the SDK. In Rust it’s a ClientInitGuard, in JavaScript it could be a helper object with a close method that is awaitable.
You should be able to call this multiple times where calling it a second time either tears down the previous client or decrements a refcount for the previous client etc.
Calling this multiple times should be used for testing only. It’s undefined what happens if you call init on anything but application startup.
A user has to call init once but it’s permissible to call this with a disabled DSN of sorts. Might for instance be no parameter passed etc.
Additionally it also sets up all default integrations.
capture_event(event): Takes an already assembled event and dispatches it to the currently active hub. The event object can be a plain dictionary or a typed object whatever makes more sense in the SDK. It should follow the native protocol as close as possible ignoring platform specific renames (case styles etc.).capture_exception(error): Report an error or exception object. Depending on the platform different parameters are possible. The most obvious version accepts just an error object but also variations are possible where no error is passed and the current exception is used.capture_message(message, level): Reports a message. The level can be optional in language with default parameters in which case it should default toinfo.add_breadcrumb(crumb): Adds a new breadcrumb to the scope. If the total number of breadcrumbs exceeds themax_breadcrumbssetting, the SDK should remove the oldest breadcrumb. This works like the Hub API with regards to whatcrumbcan be. If the SDK is disabled, it should ignore the breadcrumb.configure_scope(callback): Calls a callback with a scope object that can be reconfigured. This is used to attach contextual data for future events in the same scope.last_event_id(): Should return the last event ID emitted by the current scope. This is for instance used to implement user feedback dialogs.start_session(): Stores a session on the current scope and starts tracking it. This normally attaches a brand new session to the scope, and implicitly ends any already existing session.end_session(): Ends the session, setting an appropriatestatusandduration, and enqueues it for sending to Sentry.
All SDKs should have the concept of concurrency safe context storage. What this means depends on the language. The basic idea is that a user of the SDK can call a method to safely provide additional context information for all events that are about to be recorded.
This is implemented as a thread local stack in most languages, but in some (such as JavaScript) it might be global under the assumption that this is something that makes sense in the environment.
Here are some common concurrency patterns:
Thread bound hub: In that pattern each thread gets its own "hub" which internally manages a stack of scopes. If that pattern is followed one thread (the one that calls
init()) becomes the "main" hub which is used as the base for newly spawned threads which will get a hub that is based on the main hub (but otherwise independent).Internally scoped hub: On some platforms such as .NET ambient data is available in which case the Hub can internally manage the scopes.
Dummy hub: On some platforms concurrency just doesn't inherently exist. In that case the hub might be entirely absent or just be a singleton without concurrency management.
Under normal circumstances the hub consists of a stack of clients and scopes.
The SDK maintains two variables: The main hub (a global variable) and the current hub (a variable local to the current thread or execution context, also sometimes known as async local or context local)
Hub::new(client, scope): Creates a new hub with the given client and scope. The client can be reused between hubs. The scope should be owned by the hub (make a clone if necessary)Hub::new_from_top(hub)/ alternatively native constructor overloads: Creates a new hub by cloning the top stack of another hub.get_current_hub()/Hub::current()/Hub::get_current(): Global function or static function to return the current (thread's) hubget_main_hub()/Hub::main()/Hub::get_main(): In languages where the main thread is special ("Thread bound hub" model) this returns the main thread’s hub instead of the current thread’s hub. This might not exist in all languages.Hub::capture_event/Hub::capture_message/Hub::capture_exceptionCapture message / exception call into capture event.capture_eventmerges the event passed with the scope data and dispatches to the client. As an additional argument it also takes a Hint.For the hint parameter see hints.
Hub::push_scope(): Pushes a new scope layer that inherits the previous data. This should return a disposable or stack guard for languages where it makes sense. When the "internally scoped hub" concurrency model is used calls to this are often necessary as otherwise a scope might be accidentally incorrectly shared.Hub::with_scope(callback)(optional): In Python this could be a context manager, in Ruby a block function. Pushes and pops a scope for integration work.Hub::pop_scope()(optional): Only exists in languages without better resource management. Better to have this function on a return value ofpush_scopeor to usewith_scope. This is also sometimes calledpop_scope_unsafeto indicate that this method should not be used directly.Hub::configure_scope(callback): Invokes the callback with a mutable reference to the scope for modifications. This can also be awithstatement in languages that have it (Python). If no active client is bound to this hub, the SDK should not invoke the callback.Hub::add_breadcrumb(crumb, hint): Adds a breadcrumb to the current scope.- The argument supported should be:
- function that creates a breadcrumb
- an already created breadcrumb object
- a list of breadcrumbs (optional)
- In languages where we do not have a basic form of overloading only a raw breadcrumb object should be accepted.
The SDK should ignore the breadcrumb if no active client is bound to this hub.
For the hint parameter see hints.
- The argument supported should be:
Hub::client()/Hub::get_client()(optional): Accessor or getter that returns the current client orNone.Hub::bind_client(new_client): Binds a different client to the hub. If the hub is also the owner of the client that was created byinitit needs to keep a reference to it still if the hub is the object responsible for disposing it.Hub::unbind_client()(optional): Optional way to unbind for languages wherebind_clientdoes not accept nullables.Hub::last_event_id(): Should return the last event ID emitted by the current scope. This is for instance used to implement user feedback dialogs.Hub::run(hub, callback)hub.run(callback),run_in_hub(hub, callback)(optional): Runs a callback with the hub bound as the current hub.
A scope holds data that should implicitly be sent with Sentry events. It can hold context data, extra parameters, level overrides, fingerprints etc.
The user can modify the current scope (to set extra, tags, current user) through the global function configure_scope. configure_scope takes a callback function to which it passes the current scope.
The reason for this callback-based API is efficiency. If the SDK is disabled, it should not invoke the callback, thus avoiding unnecessary work.
Sentry.configureScope((scope) =>
scope.setExtra("character_name", "Mighty Fighter"),
);
scope.set_user(user): Shallow merges user configuration (email,username, …). Removing user data is SDK-defined, either with aremove_userfunction or by passing nothing as data.scope.set_extra(key, value): Sets the extra key to an arbitrary value, overwriting a potential previous value. Removing a key is SDK-defined, either with aremove_extrafunction or by passing nothing as data. This is deprecated functionality and users should be encouraged to use contexts instead.scope.set_extras(extras): Sets an object with key/value pairs, convenience function instead of multipleset_extracalls. As withset_extrathis is considered deprecated functionality.scope.set_tag(key, value): Sets the tag to a string value, overwriting a potential previous value. Removing a key is SDK-defined, either with aremove_tagfunction or by passing nothing as data.scope.set_tags(tags): Sets an object with key/value pairs, convenience function instead of multipleset_tagcalls.scope.set_context(key, value): Sets the context key to a value, overwriting a potential previous value. Removing a key is SDK-defined, either with aremove_contextfunction or by passing nothing as data. The types are sdk specified.scope.set_level(level): Sets the level of all events sent within this scope.scope.set_transaction(transaction_name): Sets the name of the current transaction.scope.set_fingerprint(fingerprint[]): Sets the fingerprint to group specific events togetherscope.add_event_processor(processor): Registers an event processor function. It takes an event and returns a new event orNoneto drop it. This is the basis of many integrations.scope.add_error_processor(processor)(optional): Registers an error processor function. It takes an event and exception object and returns a new event orNoneto drop it. This can be used to extract additional information out of an exception object that the SDK cannot extract itself.scope.clear(): Resets a scope to default values while keeping all registered event processors. This does not affect either child or parent scopes.scope.add_breadcrumb(breadcrumb): Adds a breadcrumb to the current scope.scope.clear_breadcrumbs(): Deletes current breadcrumbs from the scope.scope.apply_to_event(event[, max_breadcrumbs]): Applies the scope data to the given event object. This also applies the event processors stored in the scope internally. Some implementations might want to set a max breadcrumbs count here.
A Client is the part of the SDK that is responsible for event creation. To give an example, the Client should convert an exception to a Sentry event. The Client should be stateless, it gets the Scope injected and delegates the work of sending the event to the Transport.
Client::from_config(config): (alternatively normal constructor) This takes typically an object with options + dsn.Client::capture_event(event, scope): Captures the event by merging it with other data with defaults from the client. In addition, if a scope is passed to this system, the data from the scope passes it to the internal transport.Client::close(timeout): Flushes out the queue for up to timeout seconds. If the client can guarantee delivery of events only up to the current point in time this is preferred. This might block for timeout seconds. The client should be disabled or disposed after close is calledClient::flush(timeout): Same asclosedifference is that the client is NOT disposed after calling flush
Optionally an additional parameter is supported to event capturing and breadcrumb adding: a hint.
A hint is SDK specific but provides high level information about the origin of the event. For instance if an exception was captured the hint might carry the original exception object. Not all SDKs are required to provide this. The parameter however is reserved for this purpose.
An event captured by capture_event is processed in the following order. Note: The event can be discarded at any of the stages, at which point no further processing happens.
- If the SDK is disabled, Sentry discards the event right away.
- The client samples events as defined by the configured sample rate. Events may be discarded randomly, according to the sample rate.
- The scope is applied, using
apply_to_event. The scope’s event processors are invoked in order. - Sentry invokes the before-send hook.
- Sentry passes the event to the configured transport. The transport can discard the event if it does not have a valid DSN; its internal queue is full; or due to rate limiting, as requested by the server.
Many options are standardized across SDKs. For a list of these refer to the main options documentation.
Integrations allow you to configure and extend SDK functionality in a modular way. We generally recommend adding SDK features (like breadcrumbs, context, etc.) through integrations rather than directly in the SDK so they can be enabled or disabled as needed.
An integration should be configurable through the SDK's options. This is typically using a integrations key in the SDK options, which accepts an array of integration instances. The integration instances should be created with the necessary configuration and then passed to the SDK.
Sentry.init({
integrations: [Sentry.browserTracingIntegration()],
});
By default, initializing the Sentry SDK will automatically enable a set of default integrations that define baseline functionality. SDKs should expose a way to disable these default integrations, or to individually enable or disable specific default integrations.
Under the hood, the client should own the integration instances and be responsible for calling the integration's methods at the appropriate times.
The API surface of integrations does not follow a common interface in the SDKs. Below is an example of what the integration interface looks like in the JavaScript SDKs, which is a good starting point to design an integration API in other SDKs.
/** Integration interface */
export interface Integration {
/**
* The name of the integration. Should be unique to avoid conflicts with other integrations.
*/
name: string;
/**
* This hook is only called once, even if multiple clients are created.
* It does not receive any arguments, and should only use for e.g. global monkey patching and similar things.
*/
setupOnce?(): void;
/**
* Set up an integration for the given client.
* Receives the client as argument.
*
* Whenever possible, prefer this over `setupOnce`, as that is only run for the first client,
* whereas `setup` runs for each client. Only truly global things (e.g. registering global handlers)
* should be done in `setupOnce`.
*/
setup?(client: Client): void;
/**
* This hook is triggered after `setupOnce()` and `setup()` have been called for all integrations.
* You can use it if it is important that all other integrations have been run before.
*/
afterAllSetup?(client: Client): void;
/**
* An optional hook that allows to preprocess an event _before_ it is passed to all other event processors.
*/
preprocessEvent?(
event: Event,
hint: EventHint | undefined,
client: Client,
): void;
/**
* An optional hook that allows to process an event.
* Return `null` to drop the event, or mutate the event & return it.
* This receives the client that the integration was installed for as third argument.
*/
processEvent?(
event: Event,
hint: EventHint,
client: Client,
): Event | null | PromiseLike<Event | null>;
}
Adding new behaviour to an SDK (like new instrumentation or event processing functionality) should be done via an integration if possible. This integration can either be default (opt-out) or opt-in depending on the use case.
The biggest thing that influences if a new integration should be default or opt-in is the overhead it adds. Default integrations should be lightweight and not add significant overhead to the SDK. If a piece of instrumentation can cause performance issues, it should be opt-in, and the user should be made aware of the potential impact.
In addition, default integrations should be well-tested. If a new integration is enabled by default, it should be tested in all supported environments and configurations to ensure it doesn't cause issues. We should not be adding new default integrations without proper testing.
If a default integration creates a high volume of new data (for example a lot spans or transactions), it should be opt-in and only made default in a new major version of the SDK. This is to prevent users from being surprised by the new data and to prevent potential performance issues. In the case of spans we especially have to take care to ensure that the spans generated by a new integration don't make traces too noisy, which hurts their usefulness.
In general we can examine the following questions to determine if a new integration should be default or opt-in:
- Does the integration add significant overhead to the SDK?
- Does the integration create a high volume of new data?
- Is the potential for issues in the integration low?
- Does the integration have potential compatibility issues with other integrations or the SDK itself?
Integration authors and SDK maintainers should work together to determine the best approach for new integrations based on the answers to these questions.
If an integration is introduced as opt-in, it can be made default in a future version of the SDK if it is well-tested and doesn't cause issues.
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").